R and RDS support
R is a programming language that is popular for statistical analysis. One reason for this popularity is that there are lots of R packages for performing advanced and rare analyses. One of the principles of Columnal is interoperability: I'd like to make it easy for users to take data from R, put data back into R and make use of R's extensive library of packages. The latest version of Columnal (available now) includes all this functionality, as demonstrated in the video shown just below. In this post I'll detail a few of the challenges of implementing this interoperability with R.
Data transfer
Transferring data between Columnal and R requires reading and writing a serialization format that R understands. R can already read and write many formats, so there is no need to invent another. One obvious choice is a text format like CSV. The problem with plain text formats is that they carry no type information. If you have a text column with "1" and "2", this will appear to be a numeric column when you re-import. The string "12:34" might be taken as a time value, and so on. R does keep track of much of this type information, but whereas the CSV format discards it, R's own RDS data format does contain this information, so RDS is a good candidate format.
The difficulty of RDS is that it is a binary format that isn't completely documented. There are some C libraries that can read RDS, but calling C from Java (which Columnal is written in) is awkward, and some libraries I looked at didn't seem complete when I tried them. So I ended up writing my own reader and writer for RDS, via a combination of some docs and backwards engineering the format from the R source code, which itself is written in C.
One challenge with reading RDS is that prior to R 3.5.0, the format had a neat, small set of types that it could contain. The newer versions can feature something called altreps (alternative representations) which carry various benefits in R, but provide a headache for anyone else looking to use the RDS format because you have a lot more possible data types to add support for. I've added support for the altreps that I have encountered, but there are yet more that I need to support.
Type systems
One challenge of converting between programming languages is mapping all the types. Thankfully, Columnal and R have a reasonable mapping for most types:
| Columnal type | R type |
|---|---|
| Number | int, double |
| Text | character |
| Boolean | logical |
| Date/time types | Date, POSIXct |
| Tagged types | Factors, NA, ??? |
| Records | Named list |
| Lists | list |
One slight complication is that R's built-in data frame class does not support lists as cell values. Therefore if you export a Columnal table with records or lists, we generate a tibble instead of a data frame.
Tagged types
The main difficult item to convert is Columnal's tagged types, also known as variant types, algebraic data types and several other names. Broadly, these can be separated into three major use cases:
- Tags with no inner values, such as a
Day Of Weektype withMon, Tue, Wed, Thu, Fri, Sat, Sunvalues. Optionaltype, which is eitherNoneorIs(inner value)- All other cases: types that have a mix of tags with and without inner values.
Case 1 maps neatly on to R's factors. Case 2 is represented in R by having NA values for missing values. A slight awkwardness here is that Columnal requires you to deliberately identify whether a column can contain missing values, whereas R lets them occur anywhere. Therefore the type of a Columnal column depends on the values in an R column: if there are no NAs in a numeric column it will have type Number, but if there are any NA, it will have type Optional(Number). This is a deliberate design decision in Columnal and in R that conflicts, so there i s no easier resolution.
Finally, we have case 3: complex tagged types. This is still an open question as it stands – I'm happy to hear opinions:
#rstats users: what's the usual way to flatten an algebraic data type into an R data frame column? e.g.
— Neil Brown (@neilccbrown) November 15, 2019
DateOfBirth = Missing | Invalid | DoB(Date)
Height = Metres(Number) | FeetInches(Number, Number)
A column for a tag and each inner value (with NAs), or is there another way?
Executing R
I looked at a few different ways of executing R from Java. There are live servers like Rserve, but I've had lots of trouble in the past with firewalls interfering with socket connections on users' machines, so I wasn't keen on this solution. There is an entire re-implementation of R in Java, but as I understand it, not all R packages are supported.
So instead, Columnal executes an R script from Java using the local installation of R on the user's machine. It loads any necessary Columnal source data from a temporary RDS file, executes the user's R code, then saves the result back to an RDS file that is then reloaded into Columnal, as shown in the diagram below:
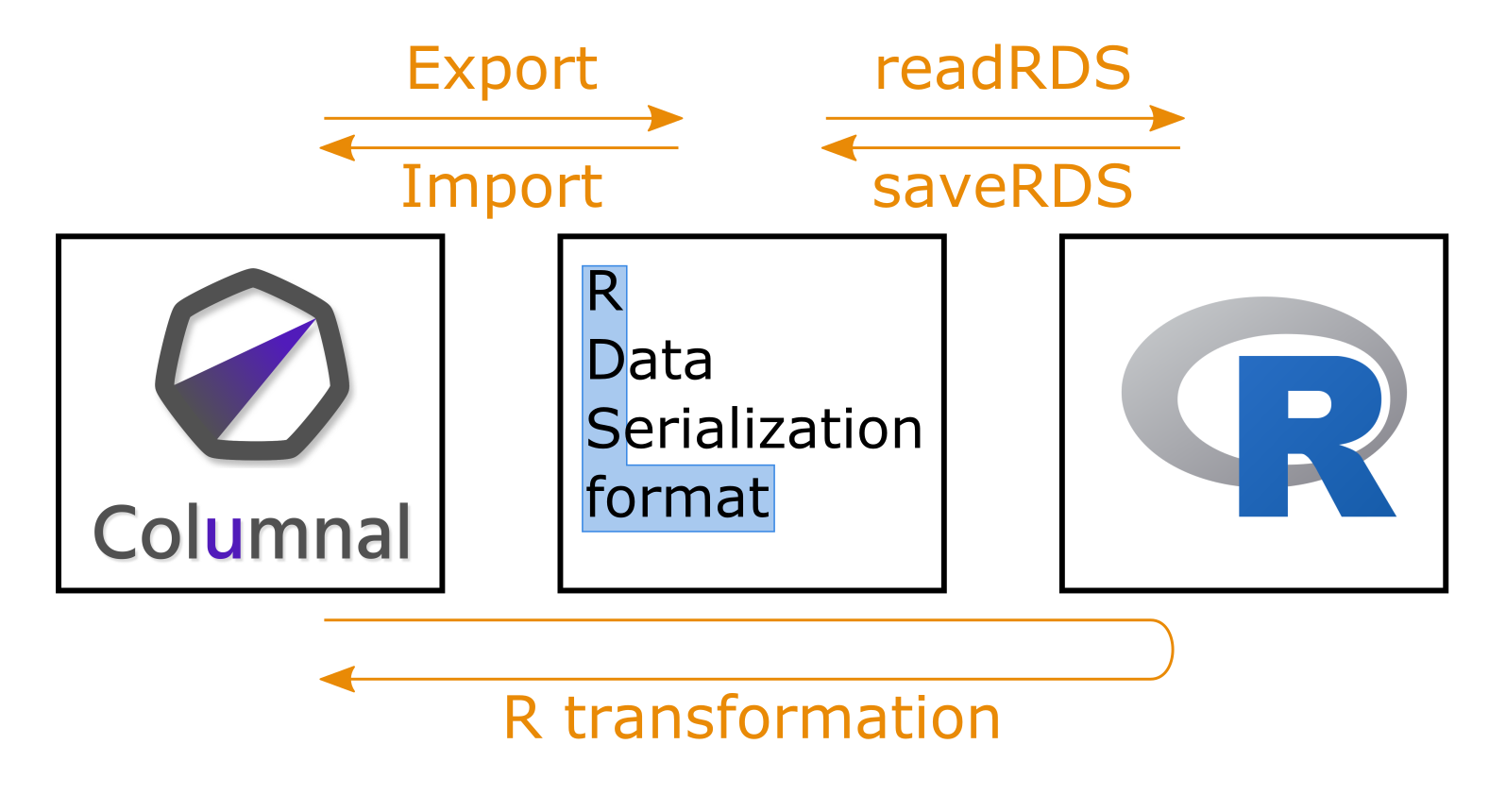
One nice feature is that the type of the result is inferred from the data, so there is no need to supply any type annotations in Columnal specifying what type is expected (which is often needed when executing arbitrary code using a Foreign Function Interface from a statically-typed language).
Impure thoughts
Up until now, all expressions and transformations in Columnal have been pure, a technical term meaning that they always return the same result if they are given the same input. The R transformation is the first one that could be impure. As a simple example, the R code might generate some random numbers using the current time as a seed, which will therefore be different on each execution.
Impurity requires interface adjustments. Until now, there was no way to "re-run" a transformation, because there's no point if it will always give the same result. You can already see in spreadsheets how impurity causes issues – if you make a RAND() call to get a random number, it re-evaluates all random number calls every time you add another RAND() call, which is very confusing and a potential source of bugs. In Columnal, an R transformation will re-evaluate either when its source tables change, or when you click the re-evaluate link in the table header.
Testing
For Columnal I use a lot of property-based testing. For those who are unfamiliar with it, property-based testing combines custom-written checks with random data generation. For example, imagine you want to test a sort function. You write some checks: the output should be in order, the output should have the same elements as the input. Then you randomly generate a lot of lists, sort each of them, and check that the property holds on all the outputs. This is good at flushing out weird corner cases, such as a bug which, say, only occurs when the input list has three duplicate elements which start next to each other in the list.
The obvious way to test the import and export using a property-based approach is a round-trip test: generate a bunch of random Columnal tables, convert them to R, load and save again in R, re-load into Columnal, and check we got back what we started with. But there are several ways in which this did not work easily:
- R uses doubles or ints for numbers. Columnal uses a decimal storage format for numbers, so you have to take care to generate numbers that will round-trip from decimal to double and back to decimal if you want the same number back.
- Similarly, R uses doubles for date-times in its POSIXct type, which only gives microsecond precision. Columnal has nanosecond precision on DateTime, so we must account for this.
- Columnal allows units-of-measure (like metres) in number types, but there's no way to preserve this information into R, so we just ignore units.
- R's POSIXct type seems to have a restriction that all the values in a column must have the same time zone, so we can only round-trip DateTimeZoned columns which all use the same time zone.
- Because all primitive values in R, even a single number, are an array, not all Columnal types can round-trip. If you were to convert literally on import, a single Columnal number would come back as a list of R numbers. But if you convert single-item R lists to a single Columnal value, as I choose to do, then Columnal lists with a single value will not survive the round-trip as a list, so that must be accounted for.
There are of course a whole host of things that R supports that Columnal does not, which would prevent round-trip tests from R to Columnal and back, but naturally I'm primarily interested in only the things which Columnal supports.
One final complication: since R expects that RDS will be saved by R, it's fairly light on error checking code when loading RDS files. I discovered that it's possible to write RDS items that R will happily load and then re-save without complaint, but if you try to access them, the R interpreter will then crash. So it's important to access the data in R as part of the round-trip test, to make sure our generated R data is valid (i.e. to try to provoke the crashes!).
The end result
Columnal now has import from RDS, export to RDS, and most useful of all, a transformation that lets you run an R expression on your Columnal data. My hope is that over time this will become less useful as Columnal adds more features in the software itself, but it's clearly useful to be able to access the wide range of existing R packages, especially when using Columnal for statistical analysis.